AI 微调
Crowdin 中的微调功能利用您的项目专属数据增强 AI 模型,使翻译符合您的风格、语气和术语。 通过利用项目中已审核的翻译及翻译记忆库(TM),微调可提升翻译质量、降低运营成本,并使 AI 性能适应您的本地化工作流程。
微调适用于使用自定义 API 凭证的受支持 AI 模型和提供商的自动翻译提示词,可创建针对您本地化需求定制的 AI 模型。
微调可提升 AI 模型的性能,具有以下优势:
- 精准度提升 – 基于您的数据训练的模型能与您的风格、语气和特定领域术语高度契合。
- 更好的上下文处理 – 通过使用项目中的真实示例训练模型,处理边界情况和复杂场景。
- 节省成本 – 微调通过启用更短且更精准的提示词来减少 token 用量。
- 增量更新 – 在新数据上训练模型,无需从头开始,节省时间和资源。
您可以创建新的微调任务、监控其进度,以及查看已完成任务的详细指标。
要创建微调任务,请按以下步骤操作:
- 打开您的个人资料并在左侧边栏中选择 AI。
- 在微调选项卡中,点击创建以设置新的微调任务。
- 配置基本参数和可选的高级参数。 高级参数通常用于复杂数据集,或针对特定领域需求微调模型时进行调整。
- (可选) 在继续之前估算微调成本。
- 点击开始微调。
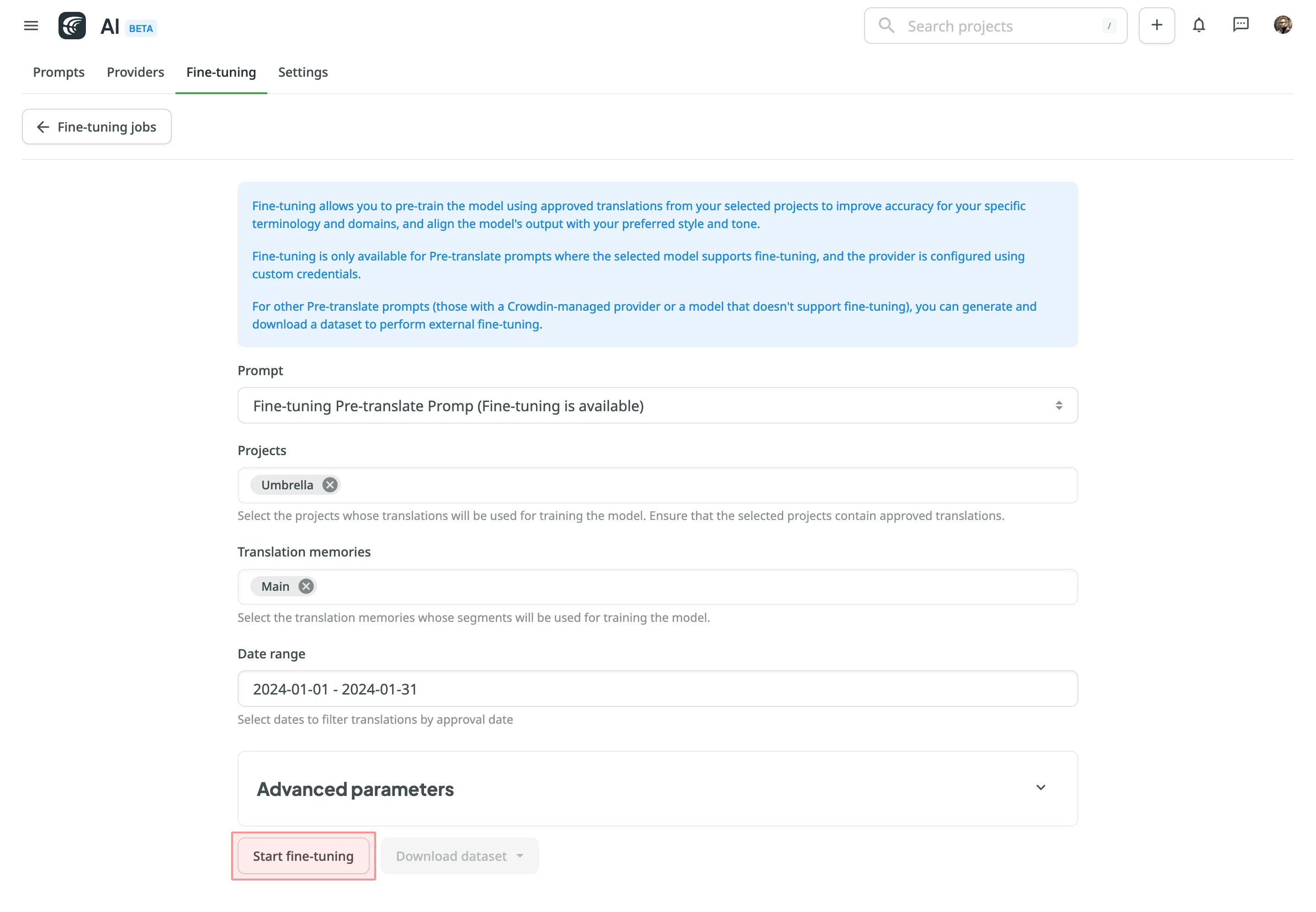
- 在微调任务部分监控微调进度,并在完成后评估结果。
在运行流程前估算微调成本,有助于确保训练在预算范围内进行,并允许您调整参数以获得最佳结果。 如果您使用的是大型数据集或运行多个微调任务,此步骤尤为有用。
要估算微调成本,请按以下步骤操作:
- 转到高级参数,将训练轮数设置为 1。
- 点击开始微调。
- 系统将计算并显示大致的微调价格。 此时,您可以:
- 如果价格符合预期,点击继续以开始实际微调。
- 点击返回以调整参数并优化配置,从而可能降低成本。
通过预先估算成本,您可以避免不必要的开支,并可尝试不同的配置,以在性能和预算之间取得适当平衡。
打开 AI 页面上的微调选项卡后,您可以查看和筛选微调任务,以监控其进度和结果。
您可以查看所有已创建微调任务的列表,其中包含以下详细信息:
- 任务 ID – 微调任务的唯一标识符。
- 状态 – 任务的当前状态(例如:进行中、已完成、失败)。
- 创建时间 – 任务创建的日期和时间。
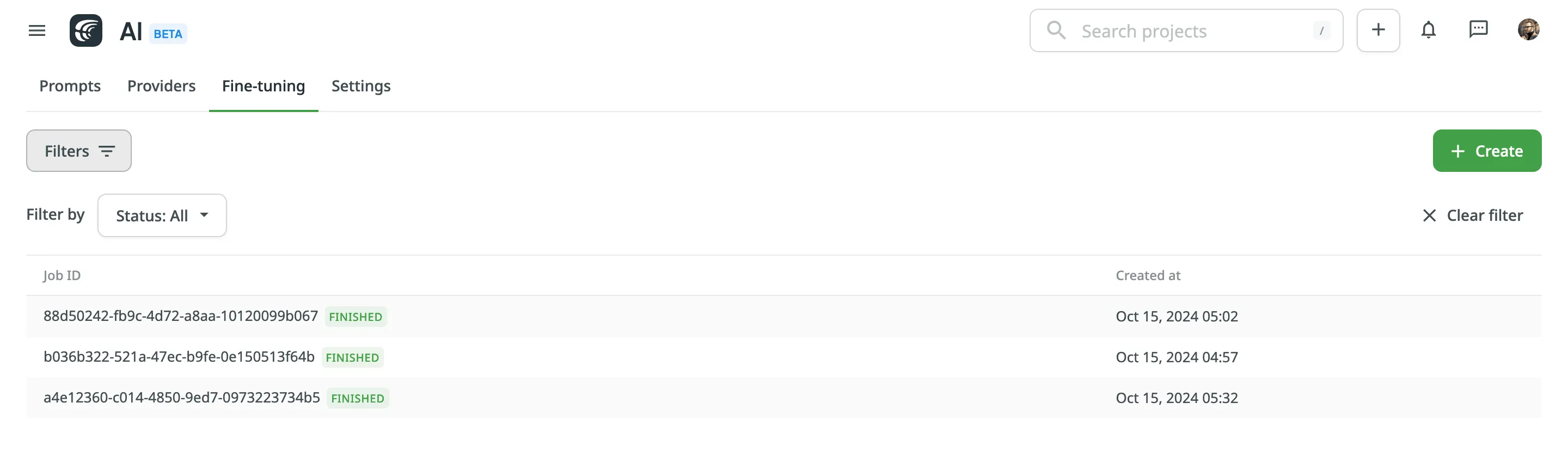
要筛选任务,请点击 并应用以下筛选条件:
- 状态:全部、已完成、进行中、失败。
点击清除筛选以重置筛选条件并显示所有任务。
双击某个任务可打开其详细指标,包括参数、结果、日志及其他相关信息。
您可以使用基本参数和高级参数配置微调任务。
启动微调需要以下参数:
- 提示词 – 选择要进行微调的自动翻译提示词。
- 项目 – 选择其翻译将用于训练的项目。 确保所选项目包含已审核的翻译。
- 翻译记忆库 – 包含用于训练数据的翻译记忆 (TM) 片段。 留空则不包含翻译记忆库。
- 日期范围 (可选) – 指定用于筛选翻译的审核日期范围。
高级参数可对微调流程提供更精细的控制,并包含训练数据集和验证数据集的相关选项。
训练数据集参数控制用于训练模型的数据。 这些设置决定数据集的大小和范围,确保其足以支持有效训练:
- 批次大小 – 训练期间每个批次中的示例数量。 较大的批次大小可降低方差,但会增加训练时间。
- 学习率乘数 – 调整学习率的缩放因子。 较小的值有助于防止过拟合,而较大的值则可加快学习速度。
- 训练轮数 – 完整遍历训练数据集的次数。 较高的值可提升精准度,但会增加成本。
- 数据集大小限制 –
- 数据集文件最大大小(字节) – 限制训练数据集的大小。
- 数据集中示例的最小数量 – 设置训练数据大小的下限。
- 数据集中示例的最大数量 – 设置训练数据大小的上限。
验证数据集用于测试微调后的模型在未见数据上的表现。 配置验证数据集是可选的,但建议进行以评估模型性能。
- 项目 – 选择与训练所用项目不同的项目。
- 翻译记忆库 – 包含用于验证的翻译记忆 (TM) 片段。
- 日期范围 – 按审核日期筛选翻译以用于验证。
- 数据集大小限制 –
- 数据集文件最大大小(字节) – 限制验证数据集的大小。
- 数据集中示例的最小数量 – 设置验证数据大小的下限。
- 数据集中示例的最大数量 – 设置验证数据大小的上限。
微调完成后,将生成一个新模型,并附带详细指标,包括训练和验证损失、任务参数及日志。 使用这些数据评估模型性能,并确定其是否已准备好集成到您的自动翻译提示词中。
关于您的微调模型的关键信息包括:
- 模型:微调模型的名称。
- 状态:任务状态(例如:进行中、已完成、失败)。
- 任务 ID:微调任务的唯一标识符。
- 基础模型:用作微调起点的初始模型。
- 输出模型:微调后生成的模型名称。
- 创建时间:任务启动的日期和时间。
关于为微调任务配置的参数详情:
- 已训练 Token 数:训练期间处理的总 token 数。
- 训练轮数:完整遍历数据集的次数。
- 批次大小:每个训练批次中的示例数量。
- 学习率乘数:学习率的缩放因子,决定模型在训练期间调整权重的速度。
用于评估微调模型性能的指标和工具:
- 训练损失:表示模型对训练数据的拟合程度。 值越低表示学习效果越好。
- 验证损失:评估模型在未见数据上的表现。 仅在配置了验证数据集时可用。
- 完整验证损失:表示模型在整个验证数据集上的总体性能,如适用。
查看结果以确定其是否满足您的要求。 如果已准备好,您可以将微调后的模型集成到您的自动翻译提示词中立即使用。
Crowdin 提供多种方式评估微调结果,包括交互式图表和详细的指标表格。
- 交互式图表 – 可视化微调指标,例如训练损失、验证损失和完整验证损失在整个训练过程中的变化。 将鼠标悬停在图表上的点,可查看特定步骤的详细信息。 您可以通过点击图表下方的标题来突出显示或隐藏特定指标。
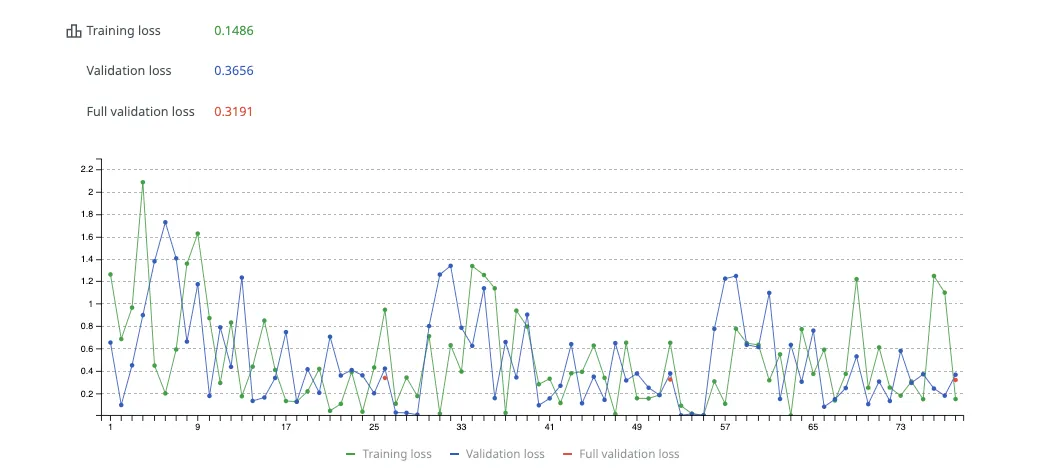
- 指标选项卡 – 以表格形式访问相同数据,获取全面概览。 该表格提供逐步细分,便于识别微调过程中的规律或问题。 各步骤中损失值的稳定下降反映了有效的训练,值越接近零表示效果越好。
这两种工具均可在微调任务详情页面中使用,帮助您分析性能趋势并有效排查异常。
消息选项卡提供 AI 提供商返回的日志,呈现任务进度的详细时间线,包括关键里程碑(例如:检查点创建、任务完成)及故障排查信息。
迭代更新微调模型,以纳入新近审核的翻译。 使用日期范围参数,避免从头开始重新训练。
示例工作流:
- 初始微调 – 使用完整数据集训练基础模型。
- 后续微调 – 仅在新近审核的翻译上进行训练,以创建更新后的模型,同时保留之前的训练数据。
增量微调非常适合持续更新的项目,使您无需从头开始重新训练即可保持模型优化。
数据集可被下载用于外部微调、外部工具使用或训练前的本地验证。
详细了解下载数据集。